
GPT-5惨遭零分打脸,顶级AI全军覆没!奥特曼AI博士级能力神话破灭
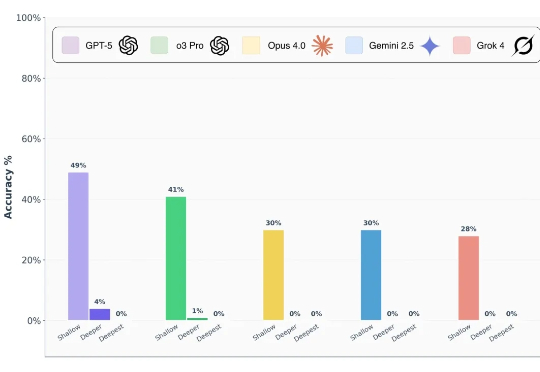
GPT-5惨遭零分打脸,顶级AI全军覆没!奥特曼AI博士级能力神话破灭顶级大模型在AAI提出的FormulaOne基准集体翻车:三层难度递进,GPT-5进阶题仅约4%正确,最深层零分;Grok 4、o3 Pro全部失手。该基准以图上MSO逻辑与动态规划生成问题,贴近路径规划等现实优化,旨在衡量超越竞赛编程的算法推理深度。
来自主题: AI技术研报
8202 点击 2025-09-17 09:30
 搜索
搜索
顶级大模型在AAI提出的FormulaOne基准集体翻车:三层难度递进,GPT-5进阶题仅约4%正确,最深层零分;Grok 4、o3 Pro全部失手。该基准以图上MSO逻辑与动态规划生成问题,贴近路径规划等现实优化,旨在衡量超越竞赛编程的算法推理深度。

最强不敢说,但最快实锤了! 刚刚,xAI发布Grok 4 Fast,生成速度高达每秒75个 token,比标准版快10倍! 从下面的动图中,我们可以直观地看出差距——当左边的Grok 4还在说“让我想一下的时候”,Grok 4 Fast已经在说:“下一个问题是什么了。”

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。

多模态的生成,是 AI 未来的方向。 最近,AI 领域的气氛正在发生微妙的变化。比如,刚刚推出了 Grok 4 的 xAI 却在重点宣传他们的视频生成模型 Grok Image。
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?
xAI又一位联创官宣离职了!AlphaStar之父Igor Babuschkin发长文告别,回忆曾带队爆肝120天造出全球最强超算,老马亲自下场致谢:没有你就没有xAI的今天。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。
奥特曼砍掉GPT-4o,防止用户沉迷;马斯克Grok 4限时免费,用「热辣模式」和拟人化角色留住用户。

刚刚,xAI 宣布,Grok 4 从现在起对全球所有用户免费开放!不是试用,不是限时,而是真正的免费。不再是鸽rok,而是Grok!使用 Auto 模式,系统会自动判断你的问题复杂度,把需要高级推理的查询路由到 Grok 4。如果你想要更多控制权,随时可以切换到 Expert 模式,让每个查询都走 Grok 4。
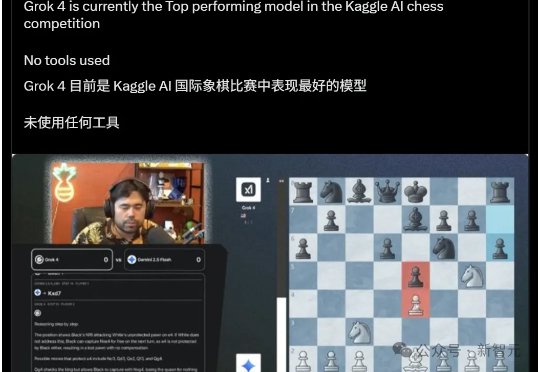
决赛前,它是沉默、精准、不可一世的冠军候选;决赛后,它成了连续送子、失误连连的背景板。Grok 4经历了从神坛到谷底的戏剧性一天,它的轰然倒塌,也成就了o3的不败王者神话。